
TL;DR: Given the pressing need for affordable scaling of mobility automation solutions, there is a need to formalise this problem. One such method can be drawn from the pages of Big O notation where the growth of data requirements can be measured given an increase of deployment scopes.
Scaling ML based autonomous systems is probably the hardest problem for reaching any profitability
Its an open secret that building mobility automation solutions is prohibitively expensive and tedious. For example, it took Waymo a few billions of $ to deploy an autonomous system in Arizona. This makes affordable scaling of these systems to new scopes (for example, different geographies), aka Operational Design Domains (ODD) indispensable. Reason being their reliance on data which is the fuel for these advanced autonomous software solution. The data here captures the driving pattern distribution that keeps changing with time, changing scopes due to geographical or temporal variations. Some examples varying driving patterns would be due to differences of
- road structures between North America and Europe,
- driving styles in Europe and Asia,
- driving patterns between night and day,
- changes in driving patterns during a sporting event or during covid,
Lack of a framework for measuring scalability for ML based autonomous mobility systems
If history of science is any indication, our ability to quantify problems and measuring effects of different solutions has far reaching benefits. Unfortunately, autonomous mobility systems and supervised ML in general doesn’t probably have a universal framework for putting a number to the scalability problem. While some companies might already have one that they use internally, in this blog post, I want to propose one inspired from the traditional algorithm complexity measurement techniques.
What are some methods for measuring algorithmic complexities
While there a few frameworks to see through how much of resources an algorithm would consume given the input size, the most popular one is the Big O notation.
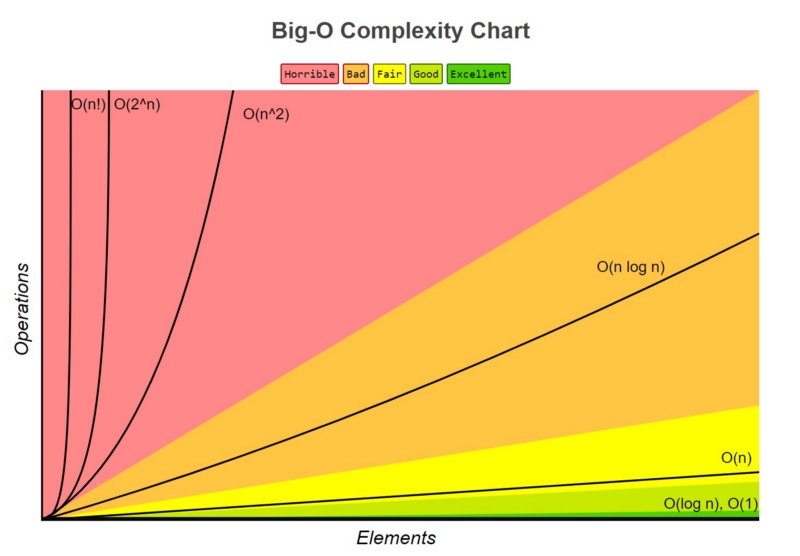
Independent variable is chosen as the number of inputs. Dependent variables are resources which are either chosen as time or space the algorithm takes. O(1) is considered best (examples being drawing a random value), and factorial the worst (eg brute force travelling salesman).
Drawing ideas from Big O notation for supervised ML and autonomous mobility solutions
Just like the traditional software frameworks, the independent and dependent variables that would make sense for ML software systems are changing scopes of deployment, and the main resource of interest – data, respectively. For ADAS/AV and other mobility solutions the changing scopes of deployment are called ODDs.

What is good enough depends on the system we are talking about. For supervised ML and mobility, a linear scale (O(n)) would be bad. Not to mention that for mobility solutions, O(n) usually translates directly to major delays and $$$. Hence, O(log(n)) is better with O(1) being the dream.
Role of Rydesafely
Facilitating safe and scalable automated mobility for everyone, be it partial automated assistance driving features, fully automation driving or last mile delivery. Core to it is our ability to measure scalability. We are pushing hard to get as close to O(1) while delivering some provable guarantees of safety through coverage arguments.
Conclusion
Ability to quantify a tough engineering problem is a superpower. It helps measuring progress and communicating intent to stakeholders easier. Rydesafely is pushing the forefronts of such techniques for mobility and will keep doing it in the future. As we move forward, it becomes crucial to put light into these frameworks from the perspectives of newer technologies such as self-supervised and transfer learning. We will do that too soon.
This article is also posted in Rydesafely’s blog here.

One thought on “Measuring scalability for autonomous mobility solutions and supervised ML”