
Lately, I have been thinking deeply (pun intended) of Imitation Learning and its prospects for enabling fully autonomous robots and cobots. This will help us not do what we really do not want to do. Well, you might say, “look Sanjay, there is nothing groundbreaking about this idea and you are definitely not the first and the last to think about it”. And I would agree to it but what is interesting in my case is what transpired to lead me to this point of writing a blog post about it. It started during one of my conversations with my friends when I visited India a month and a half ago. We talked about if we can do something about the deeply disgusting inhuman job of Manual Scavenging with AI that unfortunately still exists all across the country. Certainly, with all the buzz around capabilities of deep reinforcement learning today (especially after it equipped AI with enough learnability to shatter the grand challenge of the game of GO), and predictions of the impending singularity through it, the idea of having some form of an intelligent robot that can clean our sewers and septic tanks should not too far-fetched, right. Anyway, it was not too hard to understand very soon that the premise of such exaggerated extrapolations to what AI in near future will do is definitely not on the horizon and definitely not so for a fully autonomous scavenging robot. But wait, given the maturity of supervised learning methods that we have attained today, maybe imitation learning can help here as all we apparently would need is memorize the mapping between the right action to take given the situations in the demonstrations. So here I am today, after reading about Learning from Demonstrations (LfD) for a few weeks now, writing about it which is incentivized by both disseminating what I understand about it at this point and validating that I actually do understand it (somewhat).
I plan to cover LfD in three separate blog-posts. In this first post, I’ll walk everyone through the what I understand by LfD, why it makes sense to me to invest time in it, and a technique called Behavioral Cloning. Later in the future, I’ll cover Inverse Reinforcement Learning and some important extensions of LfD.
1. Introduction
Learning by imitation in human history has played a pivotal role in steering our evolution and continues to play a crucial role in shaping intelligent behavioural societies. Kids learn most of their daily life routines like cleaning, cooking by observing their caregivers. Hence the pursuit of a stronger AI seems to fall short without equipping the AI agents with the ability to learn useful behaviour by observing. Additionally, as more and more AI-powered systems will soon permeate into our societies in the form of self-driving cars, caregiving robots, cobots etc, this calling for devising ways for better learning by imitation makes more appeal as it opens up the possibility for even a layman person to tweak their robot’s behaviour by demonstrating their intention.

LfD (sometimes also called Imitation Learning) is an umbrella term used for any learning methodology that leverages demonstrations to learn any function of interest. The simple nature of many LfD techniques had prompted researchers for quite some time to leverage it for complicated tasks such as avoiding navigating through pedestrian trajectories ([2]), helicopter control ([3]), autonomous driving ([4]), one-shot visual transfer ([5]) etc. In this section I will first develop perspective around why LfD is significant today, followed by formalizing LfD and different ways of approaching it, then talk about unique complications arising from the nature of LfD based techniques and finally talk briefly about getting around these unique LfD problems and extensions.
2. Why do we need LfD
Very broadly, LfD has three major advantages over other learning paradigms:
- Communication of intent is easy:: The major way of communicating intent is through reward functions but reward functions are hard to design. Given the fact that LfD techniques allow communication of intent easily, methods that leverage demonstrations seem more enticing to adopt.
- Finding a good control solution is hard:: Optimization (or credit assignment) is hard, and so is exploration. Often, the converged solution is not the best possible achievable answer. However, conveying the best solution through demonstrations is an easier task. This phenomenon even exists in the real world, as it had been observed with Fosbury Flop ([7], see figure below).
- Learning from scratch is time-consuming and dangerous:: Usually learning from scratch necessitates making a catastrophic error to know that it was bad. This is unacceptable, especially in the real world. However, demonstrations can be used to effectively communicate how to avoid such situations.

3. Formalizing LfD
Let 



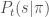


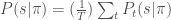



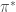
![]()
Usually, there is either limited or no access to
 would be the game screen and would be the amount of throttle and steering angles of the car.
would be the game screen and would be the amount of throttle and steering angles of the car.  can be a human demonstrator controlling a car using a joystick and can be a neural network policy.
can be a human demonstrator controlling a car using a joystick and can be a neural network policy.  would be the coupled state-action pairs at every time-step in a game run and the loss (surrogate) function can be a mean-squared error on the demonstrated and predicted actions.
would be the coupled state-action pairs at every time-step in a game run and the loss (surrogate) function can be a mean-squared error on the demonstrated and predicted actions.4. Broad kinds of LfD
Very broadly LfD methods can be categorized into three kinds:
- behavioural cloning passively,
- active behavioural cloning with an interactive demonstrator,
- inverse reinforcement learning
In this subsection, I will cover the first two categories of LfD. In the subsequent blog posts, I will also talk about inverse reinforcement learning other important extensions of LfD such as third person imitation learning and domain transfer including the inherent challenges of LfD.
4.1 Behavioral Cloning Passively
It is the simplest of all LfD techniques where the learner tries to minimize the loss function
![]()
This looks clean and intuitive. However, the applicability of behavioural cloning is terribly limited in the real world.
Why Behavioural Cloning is limited in its applicability::
Notice the difference between the induced state distributions in general LfD goal equation (first equation above) and Behavioural Cloning goal (second equation above). Usually there is a per time-step learner error in mimicking the demonstrator, which I will denote as 




As a result, Behavioural Cloning techniques work well when the demonstrations exhaustively span across the whole state-space of interest,
Behavioural Cloning can be however, made to do well by gathering demonstrator actions from nearby states to the current one. The work in [14] and [15] do this by maintaining a 3-camera setup to generated demonstrations where the inputs to the right and left camera are annotated automatically with left and right directional controls respectively. The work in [16] used a gaussian noise to generate such additional data instead of a 3-camera setup.
4.2 Active Behavioral Cloning with an Interactive Demonstrator
Interactive Demonstrator in the context of LfD is a demonstrator which can be asked for demonstrations at any state. Methods like SEARN ([11]), DAGGER ([12]) and SMILe ([10]) showed that by repetitively doing Behavioural Cloning on the interactive demonstrator feedback on the learner induced distribution of states in an online fashion (see figure below) guarantees that the accumulation of errors does not exceed 

The algorithm below shows how the skeleton of interactive LfD techniques looks like in one of its most popular techniques called DAGGER ([12)] which works the best almost invariably and serves as an ideal benchmark for newer algorithms in its category. Note that 

However, this category of LfD methods is not a silver bullet either. All interactive LfD methods assume the availability of an interactive demonstrator which is not always realistic. Moreover, they also have drawbacks that emanate from not having a notion of planning integrated into the control process such as treating all deviations equally (some of them could be catastrophic) and asking for demonstrations at every visited state even if they might not be required.
5. Conclusion
In conclusion, LfD is a promising technique without which our AI would be terribly impaired. Behavioural Cloning is a simple and intuitive technique to learn from demonstrations but comes with the catch that the learner can keep drifting away from the shown demonstrations. And whatever can go wrong does go wrong in the real world. In the future, I will write about relatively more robust methods for LfD like inverse reinforcement learning that attempts to learn the intent of the demonstrator behind the demonstrations. This has the potential to generalize better as the intent can be used to infer the right actions even at undemonstrated regions of the state-space.
I hope this post also helped you to think deeply (pun intended again) of LfD and whetted your appetite to know more.
References:
[1] Yamane, K. and Hodgins, J., 2009, October. Simultaneous tracking and balancing of humanoid robots for imitating human motion capture data. In Intelligent Robots and Systems, 2009. IROS 2009. IEEE/RSJ International Conference on (pp. 2510-2517). IEEE.
[2] Ziebart, B.D., Ratliff, N., Gallagher, G., Mertz, C., Peterson, K., Bagnell, J.A., Hebert, M., Dey, A.K. and Srinivasa, S., 2009, October. Planning-based prediction for pedestrians. In Intelligent Robots and Systems, 2009. IROS 2009. IEEE/RSJ International Conference on (pp. 3931-3936). IEEE.
[3] Coates, A., Abbeel, P. and Ng, A.Y., 2008, July. Learning for control from multiple demonstrations. In Proceedings of the 25th international conference on Machine learning (pp. 144-151). ACM.
[4] Pomerleau, D.A., 1989. Alvinn: An autonomous land vehicle in a neural network. In Advances in neural information processing systems (pp. 305-313).
[5] Duan, Y., Andrychowicz, M., Stadie, B., Ho, O.J., Schneider, J., Sutskever, I., Abbeel, P. and Zaremba, W., 2017. One-shot imitation learning. In Advances in neural information processing systems (pp. 1087-1098).
[6] Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J. and Mané, D., 2016. Concrete problems in AI safety. arXiv preprint arXiv:1606.06565.
[7] Dapena, J., 1980. Mechanics of translation in the fosbury-flop. Medicine and Science in Sports and Exercise, 12(1), pp.37-44.
[8] Wymann, B., Espié, E., Guionneau, C., Dimitrakakis, C., Coulom, R. and Sumner, A., 2000. Torcs, the open racing car simulator. Software available at http://torcs. sourceforge. net, 4, p.6.
[9] Syed, U. and Schapire, R.E., 2010. A reduction from apprenticeship learning to classification. In Advances in neural information processing systems (pp. 2253-2261).
[10] Ross, S. and Bagnell, D., 2010, March. Efficient reductions for imitation learning. In Proceedings of the thirteenth international conference on artificial intelligence and statistics(pp. 661-668).
[11] Daumé, H., Langford, J. and Marcu, D., 2009. Search-based structured prediction. Machine learning, 75(3), pp.297-325.
[12] Ross, S., Gordon, G. and Bagnell, D., 2011, June. A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the fourteenth international conference on artificial intelligence and statistics (pp. 627-635).
[13] Beygelzimer, A., Dani, V., Hayes, T., Langford, J. and Zadrozny, B., 2005, August. Error limiting reductions between classification tasks. In Proceedings of the 22nd international conference on Machine learning (pp. 49-56). ACM.
[14] Bojarski, M., Del Testa, D., Dworakowski, D., Firner, B., Flepp, B., Goyal, P., Jackel, L.D., Monfort, M., Muller, U., Zhang, J. and Zhang, X., 2016. End to end learning for self-driving cars. arXiv preprint arXiv:1604.07316.
[15] Giusti, A., Guzzi, J., Cireşan, D.C., He, F.L., Rodríguez, J.P., Fontana, F., Faessler, M., Forster, C., Schmidhuber, J., Di Caro, G. and Scaramuzza, D., 2016. A machine learning approach to visual perception of forest trails for mobile robots. IEEE Robotics and Automation Letters, 1(2), pp.661-667.
[16] Laskey, M., Lee, J., Fox, R., Dragan, A. and Goldberg, K., 2017. Dart: Noise injection for robust imitation learning. arXiv preprint arXiv:1703.09327.

One thought on “Learning from Demonstrations – I”